3. 머신러닝과 딥러닝
머신러닝
주어진 데이터를 분석하여, 특정 패턴을 분석하는 과정을 통해 정확도를 높혀나가는 학습 방식입니다.
머신러닝에서는 첫번째로 학습시키려는 데이터에 적합한 모델을 선택합니다. 이후 그 모델을 데이터에 맞게 조정하는 과정을 학습 또는 훈련이라고도 합니다.
특히 현재 머신러닝에서는 "대량의 데이터에 맞추어 확률 모델의 파라미터를 조정하는 방식"이 주류를 이룹니다.
머신러닝의 종류
데이터 제공 방식에 따라 크게 세가지 유형으로 머신러닝의 종류가 나뉩니다.
지도 학습
정답이 있는 데이터를 활용하여 정답을 예측하도록 학습시키는 방식으로, 주로 분류, 번역 등에서 사용됩니다. 높은 정확도를 보장하며, 다양한 분야에 적용할 수 있기 때문에 머신러닝 주류로 자리 잡고 있습니다. 하지만 데이터 준비에 많은 비용과 시간이 소요되는 것이 단점입니다.
비지도 학습
주어진 데이터에서 구조나 패턴을 스스로 학습하는 방식으로, 군집 분석 등에서 사용됩니다. 지도 학습과 달리 데이터 정답(라벨링) 없이 데이터를 학습하기 때문에 지도 학습보다 데이터 준비 비용이 낮습니다. 그러나 정확도를 제어하기 어렵고, 응용 범위가 제한적인 한계가 있습니다.
강화 학습
모델이 행동을 수행한 후 그 결과를 바탕으로 최적의 전략을 학습하는 방식으로, 로봇 제어, 대전 게임 등에서 사용됩니다. 모델이 추론한 결과를 바탕으로 반복적으로 탐색하며, 스스로 데이터를 수집하여 학습하는 방식입니다. 학습 과정이 복잡하고 비용이 높지만 피드백과 자율성이 중요한 작업에서 뛰어난 성능을 발휘합니다. LLM 학습 과정에서도 강화 학습을 활용합니다.
반지도 학습, 자기지도 학습 등
머신러닝이 발전하면서 모델과 데이터 세트 규모가 커져 이에 따라 지도 학습을 위한 데이터 준비 비용도 증가하고 있습니다. 이를 해결하고자 지도 학습과 비지도 학습의 장점을 결합한 반지도 학습, 비지도 데이터에서 문제와 정답을 자동으로 생성하여 지도 학습을 수행하는 자기지도 학습 등이 개발되었습니다. LLM도 자기 주도 학습을 통해 학습합니다.
추론과 학습
| 구분 | 입력 | 출력 |
|---|---|---|
| 학습 | 쌀 | 비빔밥 |
| 학습 | 배추 | 김치 |
| 학습 | 소고기 | 불고기 |
| 추론 | 떡 | ?(예측) |
| 위 테이블에서 1~3번은 입력과 출력 사이의 패턴을 분석하고 규칙을 찾아내는 학습을 나타낸 것이고, 4번은 학습된 패턴을 활용하여 출력을 예측하는 추론입니다. |
모델 파라미터의 적합도를 평가하는 지표를 손실(Loss)이라고 하며, 손실 값을 판단하기 위해 주로 "모델에서 추론한 값과 실제 값의 차이를 평균적으로 계산한 값을 이용하여 모델 파라미터를 최적화하는 방식"을 사용합니다.
모델 파라미터는 학습을 통해 조정되는 값을 의미하는데, 가중치(Weight), 편향(Bias) 등을 포함하고 있습니다.
손실 값이 작을 수록 모델의 예측 성능이 뛰어남을 나타냅니다.
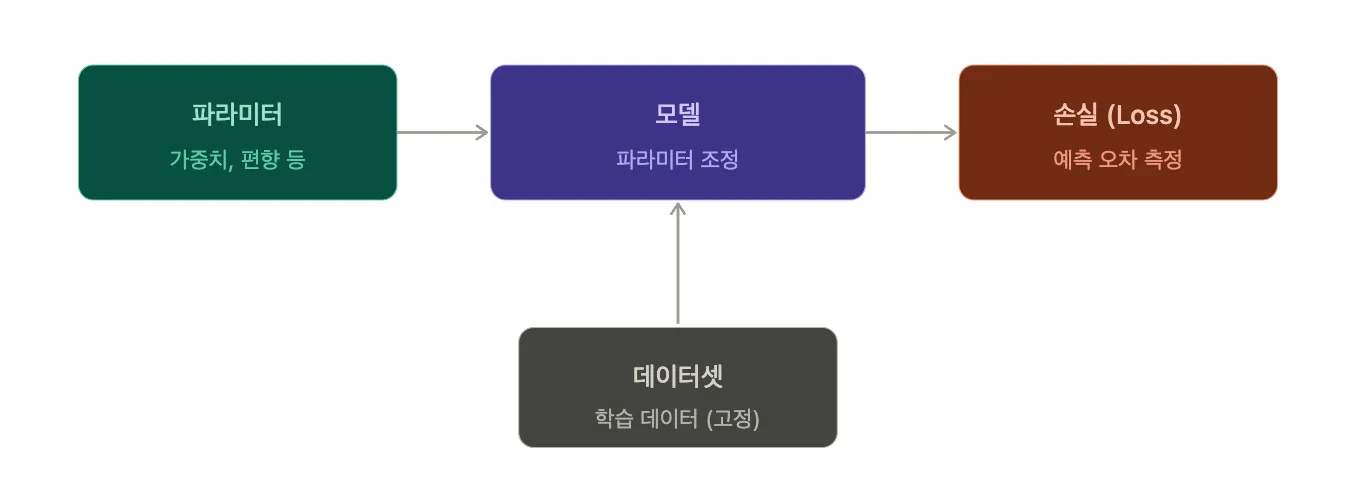
학습은 동일한 데이터가 주어질 때 가중치, 편향 등을 조절하면서 가장 손실이 적도록 파라미터를 조정하는 것이고,
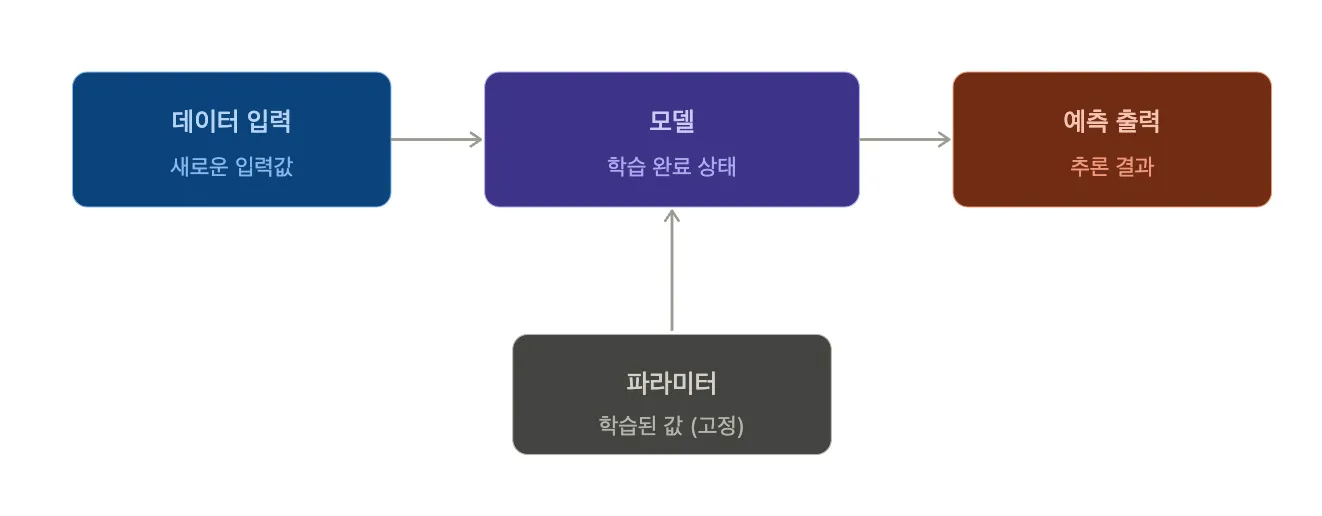
추론은 학습을 통해 얻은 최적의 파라미터를 고정한 상태에서 새로운 데이터를 입력받아 예측 값을 출력하는 과정입니다.
최적화 (여기부터!)
함수에서 가장 최적화된 결과값을 내놓는 인자를 찾는 것은 매우 어려운 문제입니다. 이러한 문제들은 최적화 문제라고 불리며, 최적화 문제에서 최적화해야 할 대상을 목적 함수라고 합니다.
머신러닝에서는 손실 함수를 목적 함수로 두어, 최적화 문제를 해결하는 방식들을 통해 구현됩니다.
최적화 방법 중에는 경사 하강법 등이 있습니다.
일반화와 과적합
과적합
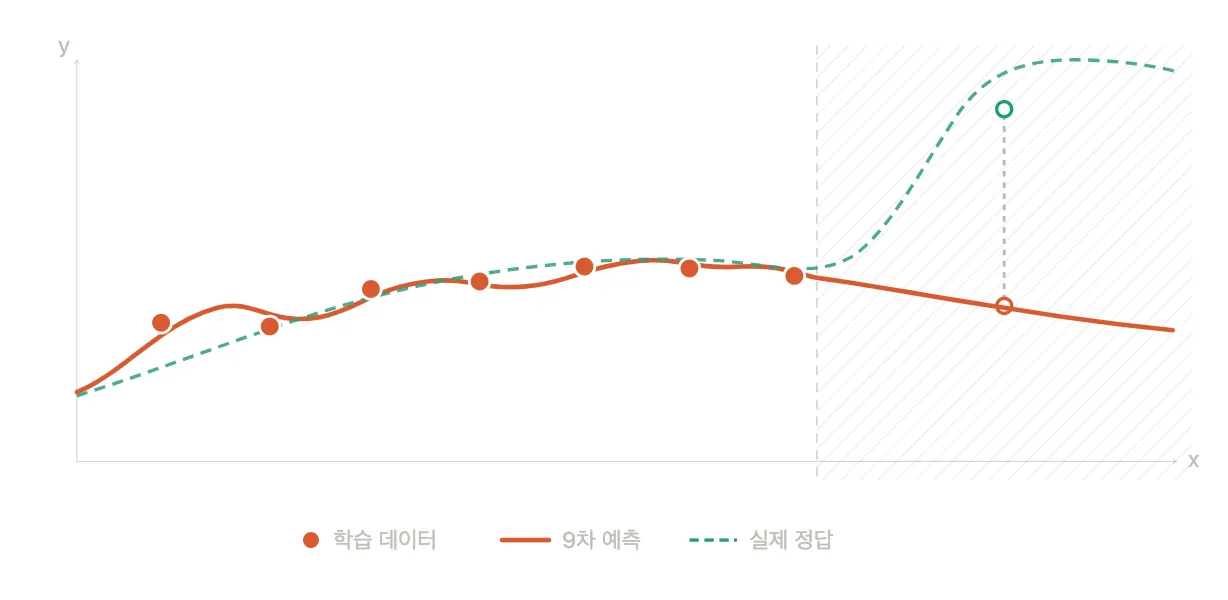
머신러닝에서의 목표는 손실(모델이 데이터에 얼마나 잘 맞는지 나타내는 값)을 최소화하는 파라미터를 찾는 것입니다. 그러나 모델이 학습 데이터에 과도하게 맞춰지는 경우가 발생할 수 있는데, 이를 과학습 또는 과적합이라고 합니다.
모델은 손실을 줄이기 위해 파라미터를 조정합니다. 그런데 모델이 지나치게 복잡하면(학습 데이터에 비해 파라미터가 과하게 많으면), 데이터의 전반적인 경향을 파악하는 대신 학습 데이터 자체를 암기하는 방향으로 파라미터가 맞춰질 수 있습니다. 이렇게 되면 학습 데이터에서는 손실이 거의 0에 가깝지만, 본 적 없는 데이터에서는 엉뚱한 예측을 내놓게 됩니다.
일반화
과적합과 반대로 학습되지 않은 데이터에서도 올바른 예측을 하는 것을 일반화라고 합니다.
일반화 성능이 높은 모델은 학습 데이터의 세부적인 값이 아닌 전반적인 경향을 학습한 모델입니다. 반대로 과적합된 모델은 학습 데이터에 대한 손실은 낮지만 새로운 데이터에 대한 손실은 높아, 일반화 성능이 낮다고 표현합니다.
일반화 성능을 측정하기 위해 학습에 사용하지 않은 별도의 데이터, 즉 검증 데이터(Validation Set)를 사용합니다. 학습 데이터의 손실과 검증 데이터의 손실을 함께 추적하면서, 두 값의 차이가 벌어지기 시작하는 시점이 과적합이 시작되는 지점입니다.
신경망
신경망은 인간 뇌의 신경 세포와 그 연결 구조를 인공적으로 모방한 모델입니다. 신경망의 목표는 인간 뇌를 그대로 재현하는 것이 아니라 AI를 구현하는 것에 있습니다.
신경망에서 사용되는 모델 구조와 학습 방식은 인간 뇌의 작동 원리와 다소 차이가 있습니다. 인간 뇌 전체를 모방하고자 하는 전뇌 아키텍쳐 연구도 진행되고 있습니다.
신경망 구조
신경망은 신경 세포(뉴런)과 유사한 구조를 가집니다. 인간의 신경 세포는 시냅스로 서로 연결되며 전기 신호를 주고받습니다. 신경망에서도 뉴런이 서로 연결되어 있으며, 전기 신호 대신 수치를 전달합니다.
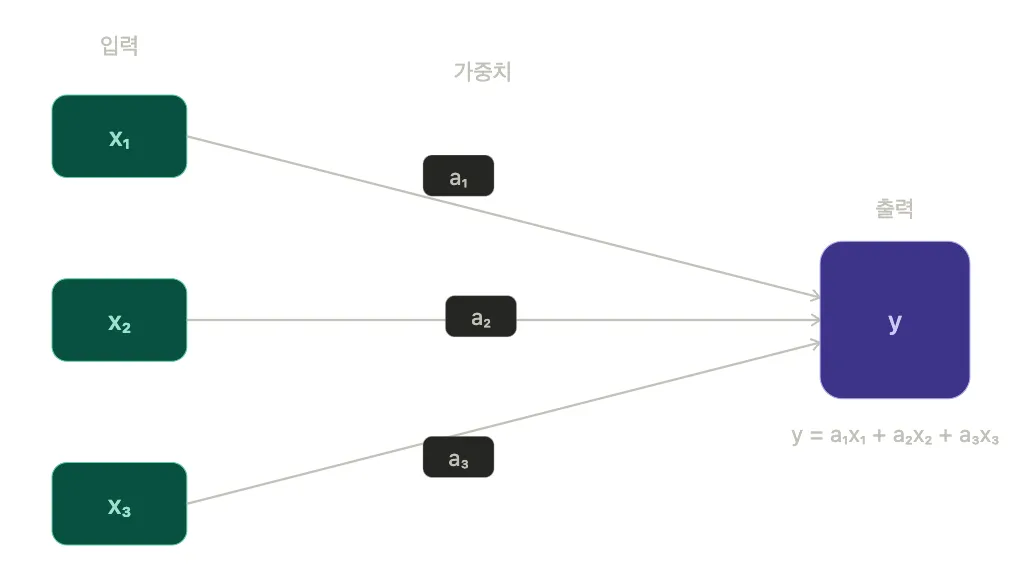
위의 x1, y와 같은 것들은 뉴런으로, 각각의 값을 가지고 다음 뉴런으로 값을 전달합니다. 왼쪽 뉴런에서 오른쪽 뉴런으로 값이 전달될 때 화살표에 표시된 가중치가 적용됩니다. 각 뉴런으로 들어오는 값의 총합이 새로운 뉴런 값이 됩니다.
이때 화살표에 a1과 같은 값들이 신경망의 파라미터라고 하며, 모델 크기는 이 파라미터 수를 의미합니다. 이러한 관계를 표현하는 함수는 선형 함수라고 합니다.
신경망을 구성하는 수식은 크게 두 가지로 나눌 수 있습니다. 하나는 선형 함수로, 신경망에서 대부분 수식이 이에 해당합니다. 그러나 선형 함수만으로는 신경망이 제대로 작동하지 않습니다. 실제로 AI 역사에서 초기 신경망은 한정된 쉬운 문제만 해결할 수 있어 발전이 정체되었습니다.
이 문제를 해결하려고 활성화 함수가 등장했습니다. 활성화 함수는 비선형 함수로, 선형 함수의 출력을 변환하는 역할을 합니다. 활성화 함수 도입은 단순한 문제만 해결할 수 있었던 신경망 한계를 극복했을 뿐만 아니라, 신경망이 복잡한 현상을 표현할 수 있도록 만들어 신경망 발전의 첫 번째 큰 돌파구가 되었습니다.
시그모이드 함수
시그모이드 함수는 대표적인 활성화 함수 중 하나입니다. 여기에서 비선형이란 직선이 아닌 곡선을 띠는 특성을 의미합니다.
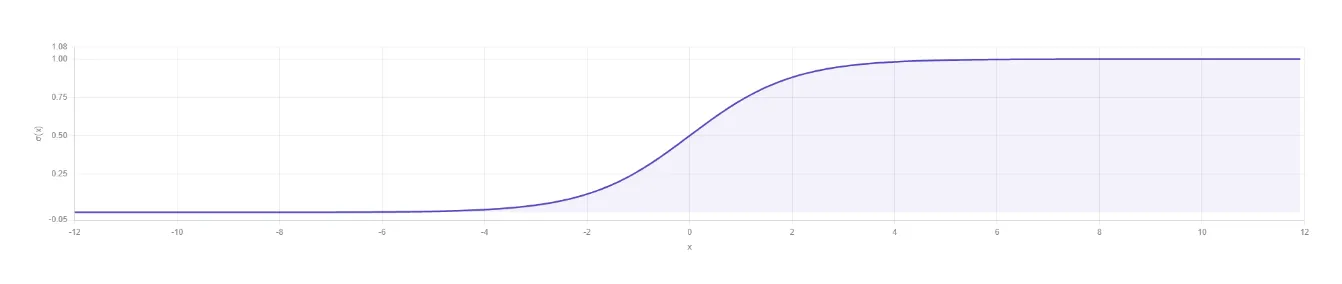
시그모이드라는 이름은 알파벳 s에 해당하는 그리스 문자 시그마에서 유래되었습니다. 그래프 형태가 S 모양이라 이렇게 이름 붙었습니다.
시그모이드 함수에 대해 검색하니까 역전파, 미분 등에 대해 나와서 더 알아보고 있습니다...
이러한 활성화 함수는 뉴런의 출력을 반환한 후 다른 뉴런의 입력으로 전달됩니다. 기본적으로 모든 신경망은 이처럼 선형 함수와 활성화 함수의 합성으로 구성됩니다.
많은 신경망에서 뉴런은 그룹화되어 있으며, 각 그룹의 출력이 다음 그룹의 입력으로 전달되는 방식으로 구성됩니다. 이러한 뉴런 그룹을 신경망의 층이라고 합니다.
이전 층의 모든 뉴런이 다음 층의 각 뉴런에 입력되는 방식을 전결합(fully connected)이라고 하며, 이렇게 전결합된 신경망을 다층 퍼셉트론이라고 합니다.
신경망에는 다층 퍼셉트론과 같은 다양한 아키텍쳐가 있으며, 여러 층으로 구성된 신경망을 심층 신경망(DNN)이라고 합니다. 이러한 심층 신경망을 학습하는 전반적인 기술을 딥러닝이라고 합니다.
신경망의 학습
경사 하강법을 이용한 학습
신경망 학습은 학습 데이터를 입력하여 출력을 얻고, 이를 정답과 비교하여 손실을 최소화하도록 신경망의 파라미터를 조정하는 과정입니다.
첨부
초기에 임시적인 파라미터가 할당된 2층 신경망입니다. 입력 (1,2,3)에 대한 정답은 Z = 0.50이라고 가정할 때, 예측이 정답에 가까워지도록 파라미터를 조금씩 조정해보겠습니다.
파란색 화살표 x_3->y_2의 가중치가 0.40인 상태에서 0.30, 0.50으로 각각 변경했을 때 출력은 각각 z = 0.71과 z = 0.73이 되었습니다. 따라서 정답인 0.50에 가까운 0.30으로 가중치를 갱신해야 합니다. 이 방식으로 모든 화살표에 가중치 갱신을 수행하고 데이터를 변경하여 반복함으로써 예측과 정답의 차이를 점차 줄일 수 있습니다.
미분 공부 중...
이 과정에서 중요한 것은 '파라미터를 조금 바꾸었을 때 손실이 줄어드는지 증가하는지' 파악하는 것입니다. 이는 '파라미터에 대한 손실의 변화율'을 계산하는 것과 같으며, 각 파라미터에서 손실의 미분을 계산하여, 기울기에 따라 신경망 모델의 학습을 할 수 있습니다. 각 파라미터의 미분 값을 모아둔 것을 경사라고 하며, 이를 사용하여 파라미터를 갱신하고 최솟값을 찾는 방법을 경사 하강법이라고 합니다.